Services
서비스
Bioinformatics
Whole Genome Resequencing
- WGRS Workflow
-
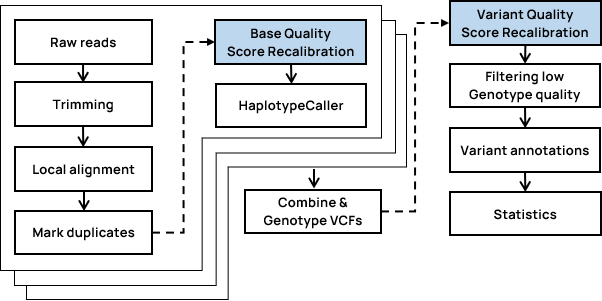
- Insertsite Workflow
-
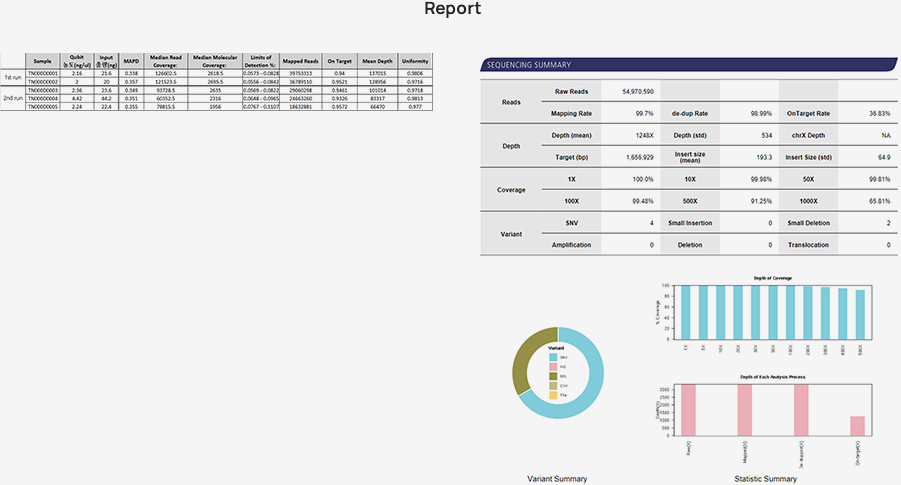
생명정보학 분석
-
Standard Analysis
Read mapping
Variants calling
Variant annotation
No content
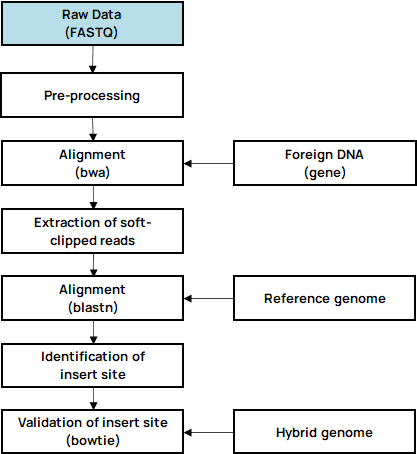
-
Advanced Analysis
Somatic variants calling
Copy number variants (CNV)
Structure variants (SV)
Multisample variants calling
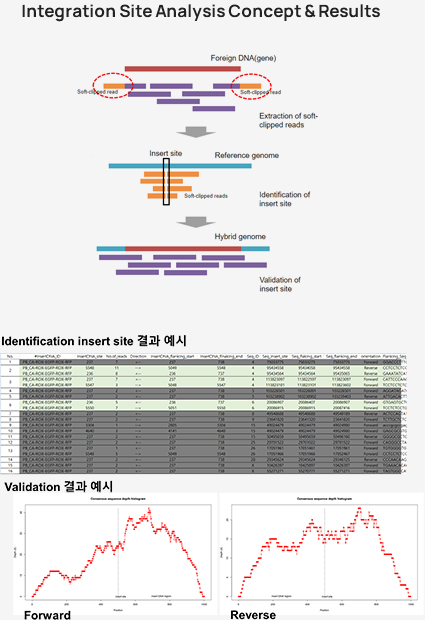
Integration site analysis
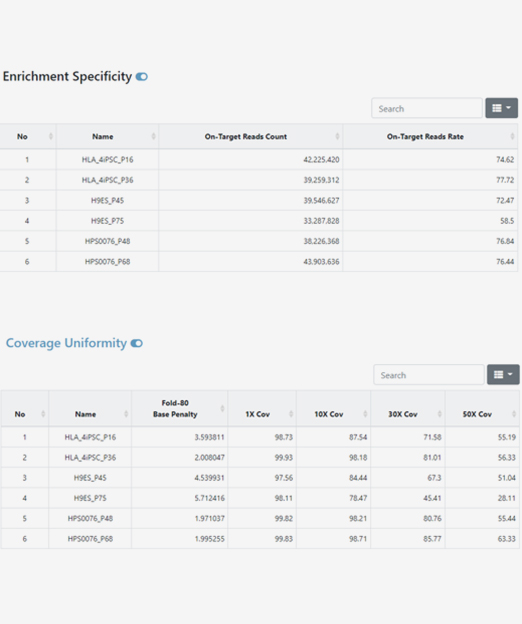
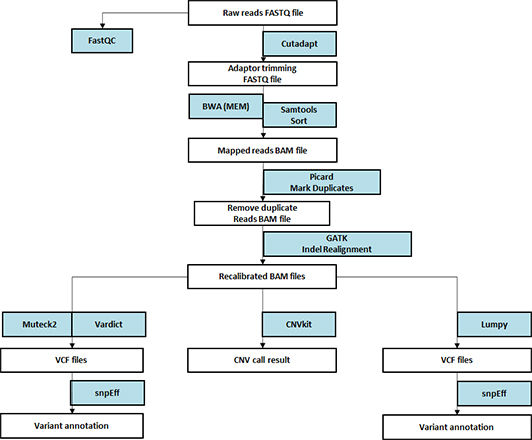
Whole Exome Sequencing
- Workflow
-
생명정보학 분석
-
Standard Analysis
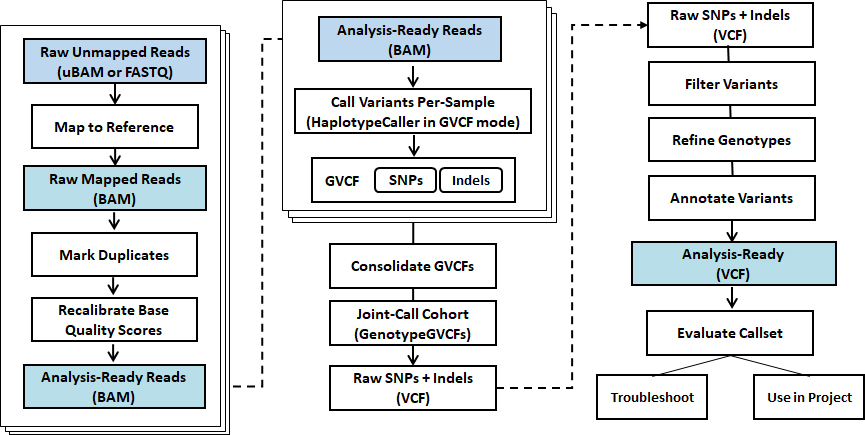
Raw read processing
Read mapping + BQSR, VQSR
Variant calling (SNV, Indels)
Variant annotation
Somatic mutation calling (For cancer genome only)
-
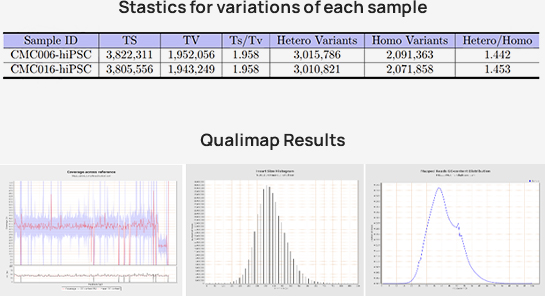
Advanced Analysis
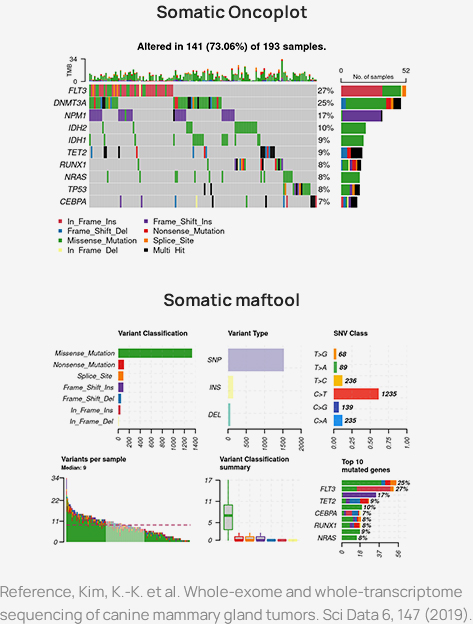
Oncoplot
No content
No content
No content
No content
Targeted Sequencing
- Workflow
-
Features & Benefits
- 임상 검사의 목적의 Targeted Sequencing Panel에 대한 변이체 탐색
- 국가 암 정보과제로 증명된 변이체 탐색
- 변이체 발굴을 통하여 임상의들의 환자 질병 치료에 대한 의사결정 과정에 가이드 제공
생명정보학 분석
-
Standard Analysis
Read mapping
Variant calling
Variant annotation
Clinical report
Advanced Analysis
Genomic rearrangement
Tumor mutation Burden (TMB), Microsatellite instability (MSI)